多執行緒架構正受到越來越多關注,因為這種架構無需增加太多晶片資源或功耗即可獲得可觀的性能增益。這種硬體多執行緒的關鍵優勢是,它能使處理器在等待快取記憶體回填的空閒週期中處理其它執行緒指令。
使消費性裝置應用程式適應多執行緒環境的代價非常小,因為大多數程式已經設計為成組的半獨立執行緒。應用程式執行緒可以分配給處理器中用於處理單執行緒的專用硬體資源。多個執行緒可以被同時分配給這種硬體,並透過共享CPU週期獲得最大效率。
嵌入式運算面臨性能障礙
消費性裝置和其它嵌入式運算產品的製造商正不斷增加Wi-Fi、VoIP、藍牙、視訊等的功能,以往功能的增加都要靠大幅提升處理器時脈速度來實現。桌上型電腦的時脈速度目前已經增加到3GHz以上,即使嵌入式裝置也接近GHz級。
但在嵌入式應用領域,這種方法很快就失去了可行性,因為大多數裝置的執行受到功耗和資源約束,限制了處理器速度的進一步提高。時脈週期速度的提高將顯著增大功耗,因此對越來越多的嵌入式裝置來說高週期速度並不可行。另外,處理器速度的進一步提高並不能帶來相應的性能改善,因為記憶體性能的提高跟不上處理器速度提高的腳步,如圖1所示。
今天的處理器速度比記憶體快很多,在許多應用領域中,處理器有一半以上的時間在等待快取記憶體管線(cache line)回填數據。每當快取記憶體丟失(cache miss)或需要外部記憶體存取時,處理器就需從記憶體加載快取記憶體管線,將這些字寫入快取記憶體,再將舊的快取記憶體管線寫進記憶體,最後恢復執行緒。
據MIPS公司表示,每千條指令接受25次快取記憶體丟失(對多媒體程式碼來說是一個合理值)的高階可合成核心如果必須等待50個快取記憶體填充週期,那麼將有50%以上的時間處於停止狀態。由於處理器速度仍在不斷提高,而且比記憶體速度的提高幅度大得多,這類問題將變得越來越突出。

圖1:處理器速度超過記憶體
多執行緒技術
多執行緒技術解決了這個難題,它可利用處理器原本用於等待記憶體存取的空閒時間處理多個平行程式的執行緒。當一個執行緒停下來等待記憶體響應時,另一個執行緒會馬上提交給處理器,因而保持運算資源的充分利用。
值得注意的是,傳統處理器不能採用這種方法,因為它需要大量指令週期才能完成執行緒之間的切換。要想使這種方法順利工作,多個應用程式執行緒必須立即有效,並能逐週期執行。
以MIPS公司的34K處理器為例,其每個軟體執行緒在執行緒環境(Thread Context,TC)上執行,一個TC包括一整套通用暫存器和一個程式計數器(program counter)。每個TC都有自己的指令預取佇列,所有佇列都完全獨立。這意味著核心能在執行緒間逐週期切換,因此避免在軟體中產生開銷。增加更多的TC只需增加少量額外矽晶片。TC共享大部份CPU硬體,包括執行單元、ALU和快取記憶體。且增加一個TC並不要求CPU擁有另外一個OS軟體執行CPU所需的CP0暫存器拷貝。
一組共享CP0暫存器及與之相關的TC即可組成一個虛擬處理單元(VPE)。一個TC執行一個執行緒,一個VPE管理一個作業系統:如果有兩個VPE,那麼就可以有兩個獨立的作業系統,或一個SMP作業系統。帶一個TC的VPE看起來就像是傳統的MIPS32架構CPU,且完全相容MIPS架構規格,它其實就是一個完整的虛擬處理器。
34K核心最多可以有9個TC和2個VPE。TC到VPE的聯繫取決於執行時間。預設情況下所有準備執行的TC都平等分享處理時間,但34K核心也能在某個特殊要求執行緒可能會‘挨餓’的情況下讓某個程式影響執行緒調度,即軟體可以控制每個執行緒的服務品質(QoS)。應用軟體與硬體策略管理器(Policy Manager)互動,策略管理器向各個TC分配動態改變的優先級。然後由硬體分發調度器將執行緒逐週期地分配給執行單元,從而滿足QoS要求。
在像34K這類多執行緒環境可大幅提升性能,因為只要一個執行緒處於等待記憶體存取狀態,另外一個執行緒就會佔用空閒下來的處理器週期。

圖2:多執行緒提高了管線效率
圖2顯示了多執行緒是如何加速程式執行速度。當只有執行緒0執行時,13個處理器週期中只有5個用於指令執行,剩下7個全部在等待快取記憶體管線的回填。在這種情況下,使用傳統處理方式的效率只有38%。
增加執行緒1就可使用上述5個用於等待的處理器週期。現在13個處理器週期中用到了10個,效率提高到77%,與最基本情況相比速度加速了一倍。增加執行緒2後可以完全加載處理器資源,13個執行指令週期可以全部用上,效率達到100%。相較基本情況速度提高263%。
採用EEMBC性能基準的測試顯示,34K核心與24KE系列產品相較,只用兩個執行緒就可以提速60%,而矽晶片尺寸只增加14%,如圖3所示。
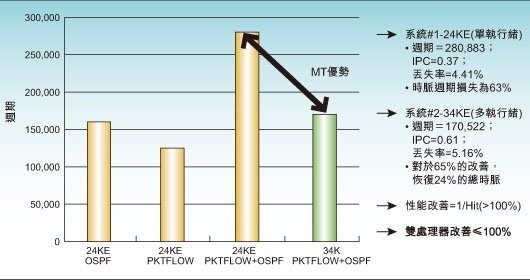
圖3:EEMBC基準性能例子顯示只用兩個執行緒性能就有60%的提高
使軟體適應多執行緒
多執行緒方法的關鍵優勢是在大多數情況下現有軟體只需做極少量的修改就能順利執行。大多數消費性程式已被寫成一系列的半獨立執行緒。每個執行緒可以被自動或人工地分配給專門的硬體TC。
如果目前正執行的執行緒由於快取記憶體丟失或其它原因引起的延遲而無法繼續執行,CPU執行機制就會從該TC切換到另外一個TC,該TC的執行緒可以在不浪費CPU週期的情況下執行。程式中執行緒越多,利用等待記憶體存取週期的可能性就越高。
多執行緒處理對使用或考慮使用RTOS的任何人來說都是非常理想的,因為RTOS程式本身就具有多執行緒特性。無需為多執行緒重新編寫RTOS程式,因為RTOS可以在程式控制下自動將程式執行緒映射為TC,其映射方式與將執行緒映射為傳統處理器的方式相同。
如果執行緒數比TC多,通常需要用到傳統的環境切換(context switch)。這些環境切換與傳統處理器中的是一樣的。RTOS保存目前任務的狀態,加載另外一個任務的環境並開始執行。多執行緒環境顯然要比傳統處理器更適合更多環境的切換,所實現的環境切換速度也更快。
各種OS的多執行緒比較
以下將就Linux和嵌入式Windows版本等作業系統與RTOS進行比較。Linux的典型即時性能在數百微秒到數毫秒。但在最壞情況下Linux即時性能並不理想。而快速RTOS可提供確定的即時性能,在單執行緒處理器上可達1到2毫秒,在多執行緒處理器上還會更快。
RTOS將唯一資源分配給唯一的TC。傳統的做法是將單浮點單元(FPU)分配給TC0。任何執行硬體級浮點運算的執行緒都需被映射為TC0,因此所有這類執行緒必須共享TC0。這就形成了多種有趣的編程選擇,特別是用硬體還是軟體實現浮點運算的選擇。
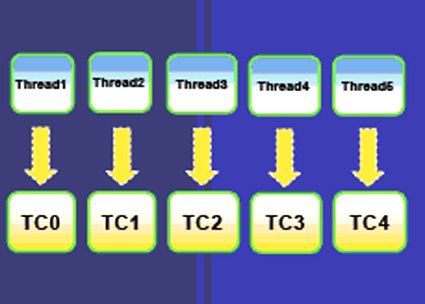
圖4:將執行緒映射為TC
用硬體實現浮點運算顯然速度會更快,但這種做法必須共享FPU。如果執行緒只做少量的浮點運算,那麼用軟體實現將更有意義,而需要密集浮點運算的執行緒通常要用硬體實現,並被映射到TC0。值得注意的是,這個修改不需要記錄,因為是否用硬體或軟體浮點實現的決定可以由編譯器切換實現。
如果程式沒有為各個執行緒定義權重,那麼程式調度器就會為所有執行緒分配相同的權重,另外也可以使用時間分段技術使執行緒依照用戶指定的權重共享CPU週期。分配權重相當於將適當比例的CPU週期分配給各個具體執行緒。執行緒權重由RTOS透明地映射為硬體TC。
一些現有程式是針對傳統處理器設計,其前提條件是假設在有高優先級的執行緒‘準備好’時,低優先級執行緒將被禁止執行。在嵌入式編程環境中,準備好的意思是執行緒執行所必須的全部條件都得到了滿足,阻止它執行的唯一因素是其優先級。
多執行緒可破壞這種條件,因為無論高優先級執行緒是否停止,低優先級執行緒都能執行。編寫取消這種狀態的程式碼可最佳化性能。
另一方面,根據這種條件編寫的現有程式碼無需修改就能執行在多執行緒處理器上,只需簡單地設定作業系統開關,使其只允許相同優先級的執行緒同時被加載到TC。在設定這個開關時,需確保為能夠平行執行的執行緒盡量分配相同的優先級。
可中斷的重要性
中斷在傳統的嵌入式應用中非常重要,因為它們提供了主要的、在許多情況下也是唯一的執行緒間切換方式。中斷在多執行緒應用中也具有相同作用,但最重要的區別是在多執行緒應用中,執行緒間的切換不僅要透過中斷,還要使用空閒CPU週期。
必須盡量避免在修改關鍵數據結構時中斷某個執行緒,同時啟用另外一個執行緒對同一結構作其它修改。這將導致數據結構處於不一致的狀態,極易引起災難性後果。
大多數傳統應用解決這個問題的方法是,當ISR或系統服務正修改RTOS中關鍵的數據結構時暫時鎖住中斷。這種方法可靠地阻止了任何其它程式跳進來對執行程式碼正使用的關鍵區域做出不恰當的修改。
然而在多執行緒環境中這種方法是不夠的,因為有可能被切換到不受中斷鎖定控制的不同TC,因而可能對關鍵區域做出修改。該問題可以利用34K架構中的DMT指令解決,當數據結構在修改狀態時可禁止多執行緒功能。
除了這些相對簡單的例外情況,程式碼在從傳統裝置移植到多執行緒裝置時無需修改就能直接執行。因此,我們能利用以往被傳統RISC處理器浪費的CPU週期,充分發揮多執行緒性能優勢。多執行緒可以滿足目前和未來需要高性能的消費性、網路、儲存和工業應用要求,而僅需增加少許成本和功耗。
與主要的競爭技術-多核心技術相較,多執行緒具有更小的矽晶片面積和更低功耗優勢,且編程簡單,現有程式只需做少量修改甚至不用修改就能執行。多核心方法也有其優勢,因此這兩種方法或許能融合出一種‘最佳方法’。但在要求高性能、低成本和最小功耗的應用領域,多執行緒是一種極具競爭力的方案。
作者:John A. Carbone
產品行銷副總裁
Express Logic公司